The Affiliation Extraction Problem
The website Digital Democracy has records of hundreds of committees and hearings for all types of legislature in the state of California. Some of these records include transcriptions of committee meetings where citizens came forward to voice their opposition or support of a particular piece of legislature being proposed or discussed. The typical sentence structure in this scenario, refered to from now on as an utterance, included some form of self introduction, a brief background of the individual, and their stance on the topic at hand.
Our group wanted to see if we could reliably extract any affiliations to organizations or cities a person may reference during a single utterance. We also wanted to be able to identify which of these affiliations the individual was most strongly connected to if possible.
System Design
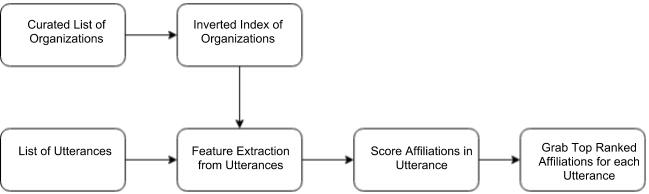
Above is a diagram showing the flow of our system. The overall design of our system involves inputting a hand-curated list of organizations and the list of spoken utterances to output the top ranked affiliation for each utterance. For each utterance, we extract a list of affiliations/features using the inverted index of organizations and score the individual affiliations using a given linear equation of weights multiplied with each normalized feature. Once all scores have been calculated, the top scoring affiliation will be outputted onto the console for further analysis and measurement.
Curating dd_Organizations
The first step of our system is curating the provided set dd_organizations. This is due to the large amount of noise in the list including many common political offices and small acronyms that cannot be reliably distinguished from short words. After curating the list we add in a list of Californian city names and common city nicknames by scraping websources with BeautifulSoup. This final list represents all affiliations that our program recognizes and will extract from the utterances we analyze.
Creating an Inverted Index
Initial runs of our program attempted to identify affiliations in an utterance through string comparison. While this allowed for a greater leeway when it came to deciding if a given word was a part of an affiliation, it proved to be much too slow. Runs using the string comparison method took +6hrs just to extract all the affiliations from the collection of utterances. This run time made testing impractical, in order to have time to refine the scoring algorithm we needed to speed up affiliation extraction. Implementing an inverted index allows us to hash affiliations and look them up in constant time rather than executing an expensive string comparison between each tokenized word in an utterance and every recognized affiliation.
Our inverted index split each recognized affiliation on white space due to the curating we had already performed on dd_organizations. This allowed us to branch on every word, which we found more useful than branching on character. Each node of the inverted index stores the text value of the current word, all the words found immediately after the current word in affiliation names (this is dependant on the words prior to the current one as well), and a boolean value denoting if the current node in the inverted index was the ending node for any affiliation.
Below is an example of an inverted index created on a small list of affiliations: Department of Labor, Department of Transportation, Department of Transportation of California, California Homeowners’ Association.

Feature Extraction
For each affiliation we extract from the utterance we must construct a feature vector, represented as a tuple, so the affiliation can be assigned a score. The first step is tokenizing the utterance using NLTK. We then iterate over the tokens looking for organization starting words. Once an organization is found its starting index, ending index, and the surrounding words are stored immediately. After the extraction algorithm has iterated over the whole utterance, and found every potential affiliation, it calculates the distance from the name of the person to each affiliation using the affiliations’ starting and ending index. Then the program extracts the two tokens to the left and right of the affiliation (4 total, returning empty strings if the affiliation is too close to the start or end of an utterance) along with the surrounding words part of speech (POS) tag. Additionally, the length of the organization name is calculated. The distance to name, length of organization name, and surrounding words are added to the feature vector tuple and a list of these tuples is passed to our algorithm for scoring for each utterance.
Scoring the Tuples

The scoring algorithm takes the summation of feature scores. Each feature score is computed by taking the product of the feature weight and the result of the feature scoring function. Our algorithm have ten features in total. They are:
| 1. Left Left Top Word Score | 6. Left Top POS Score |
|---|---|
| 2. Left Top Word Score | 7. Right Right Top POS Score |
| 3. Right Right Top Word Score | 8. Right Top POS Score |
| 4. Right Top Word Score | 9. Distance to Name Score |
| 5. Left Left Top POS Score | 10. Affiliation Name Length Score |
Features 1−4 are scored by looking up the positional word in the positional top words dictionary. For example, the left left top word score would use the word that is 2 words left of the affiliation to look up in the left left top word dictionary. The top word dictionary is generated beforehand by counting the number of occurrences a word appears in a position from a dedicated training set. The count is then normalized so all values in top words would range from zero to one. The Feature 1−4 scoring function will look up the word in the top words dictionary, if that word is found the value is returned, else the scoring function will return zero. Features 4−8 are scored similarly to Features 1−4 where a top POS dictionary is created beforehand and the scoring function will lookup the POS and return the score. The Feature 9 scoring function takes the distance (number of words away) of the affiliation from the name as input and returns the inverse of that value. During our utterance examination process, we found that affiliations that are closer to the name tends to be more accurate thus the inverse distance will tend to favor affiliations that are closer to the name. Lastly, the Feature 10 scoring function takes in a count of the number of words in the current affiliation and the number of words of the longest affiliation name and returns the quotient of the two. This is made to favor affiliations with longer names. A longer match of the organization name is bound to be more accurate.